KI in der Labormedizin: Doch nicht so intelligent?
DOI: https://doi.org/10.47184/td.2024.01.06Künstliche Intelligenz ist als Schlagwort aus dem öffentlichen Diskurs nicht mehr wegzudenken. Auch in der Laboratoriumsmedizin wird immer mehr zum Thema geforscht und es wird untersucht, wie man KI in der täglichen Routine einsetzen kann. Doch was ist eine Künstliche Intelligenz? Haben wir es hier tatsächlich mit Intelligenz zu tun? Dieser Beitrag erläutert theoretische und technische Grundlagen, die sich hinter dem viel bemühten Wort verbergen.
Schlüsselwörter: Machine Learning, Deep Learning, Large Language Model
Abseits der angespannten weltpolitischen Lage hat 2023 wohl kein anderes Thema die öffentliche Diskussion mehr bestimmt als die Künstliche Intelligenz (KI). ChatGPT und andere große Sprachmodelle füllen die Feeds der sozialen Medien, und zwischen den Tech-Konzernen ist der Kampf um die besten KI-Werkzeuge entbrannt. Doch was versteht man genau unter einer KI? Dieser Artikel möchte einige grundlegende Begriffe erläutern.
Das Wort „Intelligenz“ ist vom lateinischen „intellegere“ abgeleitet und bedeutet so viel wie erkennen, einsehen oder verstehen. Im engeren Sinne versteht man unter Intelligenz die kognitive Fähigkeit, Probleme zu lösen, wobei zwischen logischen, sprachlichen, mathematischen und sinnorientierten Problemen unterschieden wird. Neben dieser allgemeinen Definition existieren weitere Definitionen, die jeweils andere Aspekte des Begriffes herausheben. Der Pionier der kognitiven Entwicklungspsychologie Jean Piaget beschrieb Intelligenz zum Beispiel als „das, was man einsetzt, wenn man nicht weiß, was man tun soll.“
Angesichts dieser Definitionsvielfalt für die humane Intelligenz (HI) ist es somit umso schwerer zu definieren, was unter Künstlicher Intelligenz verstanden werden kann. Eine allgemein gültige Definition gibt es bisher nicht.
ChatGPT selbst liefert folgende Erklärung: „Künstliche Intelligenz (KI) bezieht sich auf die Fähigkeit von Computern, Aufgaben auszuführen, die normalerweise menschliche Intelligenz erfordern. Diese Aufgaben umfassen Problemlösung, Spracherkennung, Lernen, Planung, Wahrnehmung und Entscheidungsfindung. KI-Systeme verwenden Algorithmen und Modelle, die es ihnen ermöglichen, aus Daten zu lernen, Muster zu erkennen und Aufgaben eigenständig zu erledigen.“ [1].
Somit wird Künstliche Intelligenz als Überbegriff für Algorithmen verwendet, die explizites Wissen repräsentieren (zum Beispiel Knowledge Graphs oder Expertensysteme) oder auf Basis von Daten solches Wissen lernen und neue Erkenntnisse generieren können. Ob diese Erkenntnisse gültig und nützlich sind, muss allerdings letztlich der Mensch entscheiden.
Als ein Teilgebiet der KI wird das maschinelle Lernen (engl. Machine Learning, ML) verstanden (Abb. 1).
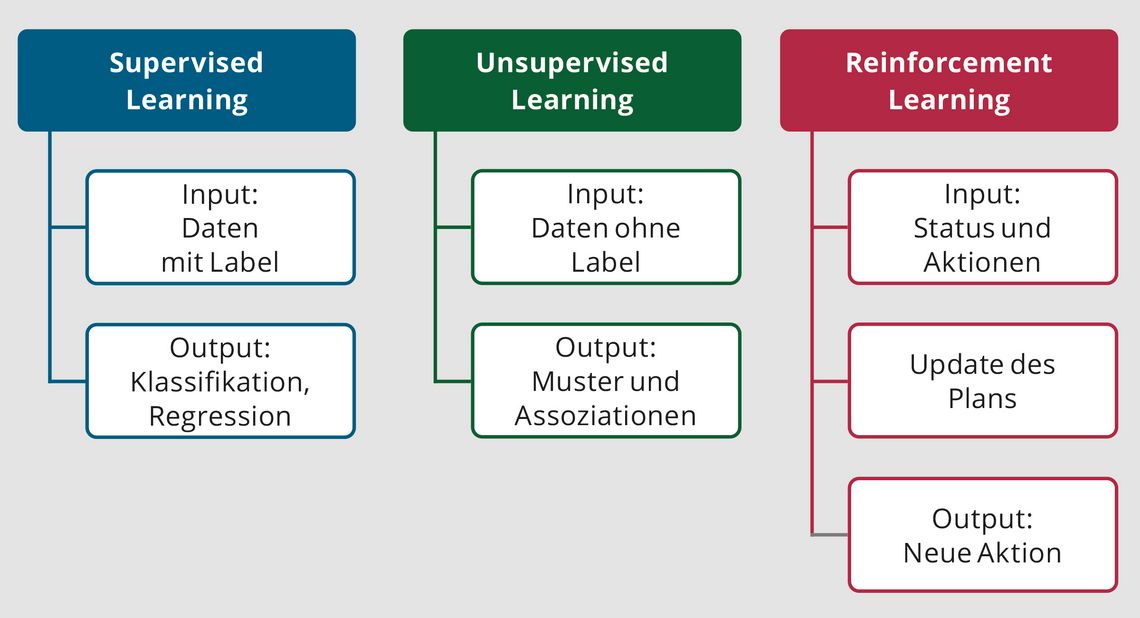
Abb. 1: Verfahren für das Machine Learning (Bild: Autor).
Es umfasst viele verschiedene Algorithmen zur Datenauswertung, Mustererkennung und Vorhersage. Als eine Sonderform des ML wird das Deep Learning (DL) abgegrenzt, das sich mit verschiedenen Formen mehrschichtiger neuronaler Netze befasst.
Machine Learning
Um das Wesen der KI besser zu verstehen, wollen wir nun eine Ebene tiefer gehen und uns dem Teilgebiet des maschinellen Lernens widmen. Grundsätzlich unterscheidet man zwischen dem überwachten Lernen (Supervised Learning) und dem nicht überwachten Lernen (Unsupervised Learning). Als weitere Kategorie wird das verstärkende Lernen (Reinforcement Learning) abgegrenzt.
Ziel des Supervised Learning ist es, nominale (z. B. Diagnosen) oder numerische (z. B. Messwerte) Zielvariablen vorherzusagen. Dafür werden Datensätze genutzt, die die erklärenden Variablen (z. B. Parameter a, b und c) und die Zielvariable (z. B. Krankheit A oder Krankheit B) enthalten. Als Ergebnis lernt der Algorithmus, aufgrund von Wertemustern die jeweilige Klasse (z. B. Krankheit A) oder aufgrund von Regressionen einen resultierenden Zahlenwert vorherzusagen (z. B. bei Parameterkonstellation A resultiert ein CRP von ca. 50 mg/l). Typische Algorithmen des Supervised Learning sind Regressionsmethoden (lineare Regression, Lasso-/Ridge-Regression u. a.), Ähnlichkeitsanalysen (z. B. K-Nearest-Neighbour-Methoden, KNN), Entscheidungsbäume (Decision Trees und Random Forests sowie Gradient Boosting) oder Trennverfahren in höherdimensionalen Datenräumen (z. B. Support-Vektor-Maschinen, SVM). Unsupervised Learning basiert dagegen auf Daten, die ohne vorherige Einordnung verarbeitet werden, um verborgene Strukturen und Zusammenhänge zu erkennen (Clustering, z. B. fünf statt zwei Diabetes-Cluster [2]). Des Weiteren kann Unsupervised Learning auch genutzt werden, um die wichtigsten Dimensionen (Variablen) eines hochdimensionalen Datensatzes zum Beispiel mittels Hauptkomponentenanalyse herauszuarbeiten.
Das Reinforcement Learning ist in der Medizin bisher kaum verbreitet. Dieser Ansatz ist dadurch gekennzeichnet, dass die Lösung eines Problems durch die Verbesserung eines „Plans zur Problemlösung“ (Policy) optimiert werden soll. Hierbei wird diese Policy auf Basis von „Bestrafungen“ und „Belohnungen“ iterativ optimiert. Ein sehr bekanntes Beispiel des Reinforcement Learning ist AlphaGo, eine KI von Google DeepMind, die das chinesische Strategiespiel Go durch Spielen gegen sich selbst gelernt hatte und letztendlich den (bis 2011) besten Go-Spieler, Lee Sedol, 2016 mit vier zu eins besiegte [3].
Vereinfacht kann gesagt werden, dass es sich bei diesen Methoden um Algorithmen der Statistik handelt, die in der Lage sind, mathematisch klar eingegrenzte Probleme zu lösen. Von einer allgemeinen Künstlichen Intelligenz, die der Intelligenz eines Menschen nahekommt (in der Informatik auch „Starke Künstliche Intelligenz“ oder „Artificial General Intelligence“ (AGI) genannt), kann aber noch keine Rede sein.
Deep Learning
Um dem vorherrschenden (Hollywood-)Bild einer KI näher zu kommen, müssen wir noch einen Schritt mehr in die Tiefe gehen und uns mit künstlichen Neuronen und dem Deep Learning (DL) beschäftigen (Abb. 2).
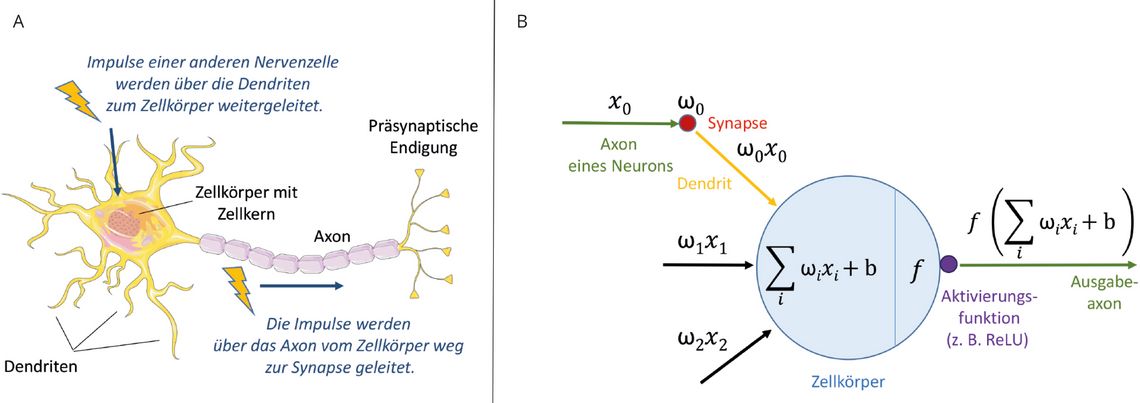
Abb. 2: Gegenüberstellung menschliches Neuron (A) und künstliches Neuron (B) (Bild: Autor/Trillium nach [4], Neuron: smart.servier.com).
Künstliche neuronale Netze sind keine Erfindung der letzten Jahre, sondern gehen ebenso wie die symbolische KI (Expertensysteme, die auf Basis von Wenn-Dann-Regeln Antworten liefern) auf Arbeiten aus den 1940er-Jahren zurück. Im Gegensatz zu Regelsystemen, die explizites menschliches Wissen reproduzieren, versuchte die Forschungsrichtung des Konnektionismus die mathematische Modellierung von Neuronen, um selbstlernende Programme zu generieren.
So wie ein Neuron die Impulse anderer Nervenzellen über seine Dendriten empfängt und ein Aktionspotenzial auslöst, wenn die ankommenden Signale einen kritischen Wert übersteigen, so erhält ein „mathematisches Neuron“ seine Inputs von vorgeschalteten Neuronen, verrechnet die Inputs mittels einer rechnerischen Aktivierungsfunktion und gibt einen Output-Wert an die nachgelagerten Neuronen weiter.
Natürlich handelt es sich hier nicht um Neuronen mit all ihrer biologischen Komplexität, sondern wie gesagt um mathematische Funktionen, die sich nur zur Veranschaulichung der Metapher der Aktionspotenziale bedienen.
Führt man Berechnungen auf Basis eines einzelnen künstlichen Neurons aus, so spricht man von einem „Perceptron“. Der wahre Zauber beginnt, wenn man mehrere Neurone zu einem künstlichen neuronalen Netz verbindet. Diese Netze verfügen über eine Eingabeschicht (Input-Layer, mitunter mehrere oder viele hunderte Neurone), „verborgene“ Zwischenschichten (Hidden Layers) und eine Ausgabeschicht (Output-Layer). Hierbei können verschiedenste mathematische Probleme (Regression, Klassifikation, Clustering, Bilderkennung, Reinforcement Learning etc.) modelliert werden.
Anwendung in der Labormedizin
Wenn Algorithmen des statistischen und tiefen Lernens in der (Laboratoriums-)Medizin eingesetzt werden und somit die Entscheidungen eines Algorithmus direkte Auswirkungen auf Diagnosestellung und Therapie haben, so muss man aus ärztlicher Sicht die Grundlagen der Entscheidungsfindung grundsätzlich kritisch hinterfragen. Diese Erklärbarkeit (explainable AI, xAI) stellt aktuell eine große Herausforderung für die KI-Forschung dar. Je komplexer ein Algorithmus ist, desto schwieriger wird es, sein Ergebnis logisch zu begründen. Während die Ergebnisse einer linearen Regression leicht zu interpretieren sind, erscheinen größere Modelle auf Basis von neuronalen Netzen oft als „Black Box“. Es gibt zwar Ansätze, die wahrscheinlichsten Entscheidungswege eines neuronalen Netzes aufzudecken (z. B. Shapley-Values), aber 100%ige Erklärbarkeit ist noch nicht erreichbar. Dies ist auch der Grund, warum in der Labormedizin aktuell vor allem bereits bekanntes Wissen mittels ML-Algorithmen reproduziert wird (z. B. Anämiediagnostik, Vorhersage des kardialen Risikos etc.). Welche Anwendungen in Routine und Wissenschaft bereits vorhanden sind, wird im Artikel auf S. 58 ff. aufgezeigt.
ChatGPT und Co.
Auch wenn Sie den bisher genannten Algorithmen und Fachbegriffen vielleicht noch nicht (bewusst) begegnet sind: Von ChatGPT hat in den letzten Monaten wahrscheinlich jeder schon gehört. Hierbei handelt es sich um ein sogenanntes „Large Language Model“ (LLM), das von der Firma OpenAI entwickelt und für die Imitation menschlicher Unterhaltungen (Chats) optimiert wurde. Es wird im Internet unter chat.openai.com zur freien Verfügung bereitgestellt. Jeder kann sich einen privaten, kostenlosen Account erstellen und sich mit dem LLM unterhalten [5]. Was verbirgt sich hinter ChatGPT?
Es handelt sich um ein „Generative Pre-trained Transformer“ (GPT)-Modell. Für die Entwicklung von Modellen, die Sprache verstehen können, ist neben dem bereits erwähnten neuronalen Netz eine Art statistisches Gedächtnis nötig: Welches Wort kam fünf Wörter vor dem letzten vor und welche Bedeutung hat es im Zusammenhang eines Satzes? Es entstanden die „Recurrent Neural Networks“ (RNNs) als Nachfolger der einfachen neuronalen Netze, die zu den „Long/Short Term Memory“ (LSTM)-Netzen weiterentwickelt wurden.
Die GPTs stellen nun eine weitere Entwicklung dieser neuronalen Netze dar. Von ihnen gibt es mittlerweile viele verschiedene, teils kommerzielle, teils öffentlich zugängliche Varianten, etwa LlaMA von Meta, Bard, PubMedGPT und MedPaLM2 von Google, Luminous von AlephAlpha sowie verschiedenen Open-Source-Modelle. Sie werden uns ganz neue Möglichkeiten der Arbeit mit Texten eröffnen.
Ob sie speziell für die Laboratoriumsmedizin nützlich sind, beispielsweise beim Verfassen von Befundtexten, ist aktuell Gegenstand verschiedener Publikationen. Erste Ergebnisse sind eher ernüchternd. Die Quintessenz mehrerer Untersuchungen zum Nutzen der LLMs bei mäßig komplexen Befundkonstellationen zeigt, dass die generierten Texte zwar für Laien durchaus intelligent klingen, von Labormedizinern aber leicht als fehlerhaft entlarvt werden können [6]. Hier bleibt die Entwicklung von LLMs, die speziell für medizinische Zwecke trainiert wurden, abzuwarten.
Intelligenz – ja oder nein?
Aktuell werden Algorithmen des ML und DL in der Labormedizin vor allem zur Aufbereitung und Bestätigung bereits bekannten Wissens eingesetzt. Sie unterstützen die menschliche Intelligenz, indem sie beispielsweise bei der Auswertung großer Datenmengen helfen, die ausufernde Fülle medizinischer Literatur sichten oder auch wertvolle Tipps für das Schreiben eigener Computerprogramme geben. Mit echter Intelligenz im Sinne der eingangs gegebenen Definition von Einsicht und Verständnis oder der Lösung neuartiger Problem hat dies aber nichts zu tun.
Autor
